Hướng dẫn sử dụng Deep Learning
Tóm tắt
AI (Artificial intelligent, trí tuệ nhân tạo) nói chung và Deep Learning nói riêng hiện nay đang là một trong những ngành nóng nhất trong bộ môn khoa học máy tính (Computer science). Chỉ trong vài năm ngắn ngủi, Deep Learning đã đẩy nhanh sự phát triển của các lĩnh vực nhỏ hơn như dịch, nhận diện giọng nói, nhận diện ảnh, … Và đồng thời mang thành tựu của những lĩnh vực đấy từ trong phòng thí nghiệm ra với công chúng - điều mà vì nhiều lý do đã từng rất khó khăn.
Đồng hành với sự phát triển đó, đã có rất nhiều tutorial, khóa học, sách, video về Deep Learning được phát hành. Chúng ta có thể dễ dàng tìm được những tài liệu với chất lượng rất cao nhưng lại hoàn toàn miễn phí. Tuy nhiên điều đó cũng dẫn đến hệ quả là với những người mới bắt đầu sẽ rất nhiều thời gian để chọn lọc được những thứ thật sự cần thiết với mình.
Để giải quyết vấn đề đó, nhóm “Deep Learning và ứng dụng” đã bắt đầu series dài kì này. Series sẽ là tổng hợp quá trình phát triển những ứng dụng nhỏ sử dụng Deep Learning mà chúng ta có thể dễ dàng dùng lại được trong công việc cũng như cuộc sống hàng ngày. Ví dụ như: nhận diện chữ viết, đọc biển số xe, tìm nhãn hàng, tìm các barcode, vân vân. Mời các bạn cùng đón xem.
Quy trình phát triển của Deep Learning
Deep Learning là một ngành nhỏ của Machine Learning. Cả hai có chung một quy trình phát triển như sau. Khi phát triển một ứng dụng sử dụng Deep Learning nói riêng mà Machine Learning nói chung thì đều phải đi qua những bước như thế.
- Định nghĩa vấn đề (Problem definition)
- Thu thập dữ liệu (Data Gathering)
- Lọc dữ liệu (Data Parsing)
- Training (tạo mô hình)
- Testing (kiểm tra độ chính xác)
- Deploying (triển khai trên sản phẩm)
Đây là qui trình chung sử dụng trong cả nghiên cứu (research) và phát triển (development). Nếu các bạn có thời gian, nên xem thêm How startup do AI để thấy rõ hơn điều này.
Hình dưới đây lấy từ Facebook Machine Learning guide (Ads team) . Đây là team chuyên về đề xuất quảng cáo (Ads), tùy vào lịch sử truy cập web mà họ sẽ đề xuất một quảng cáo tương ứng. Chúng ta thấy họ cũng đi theo qui trình như trên.
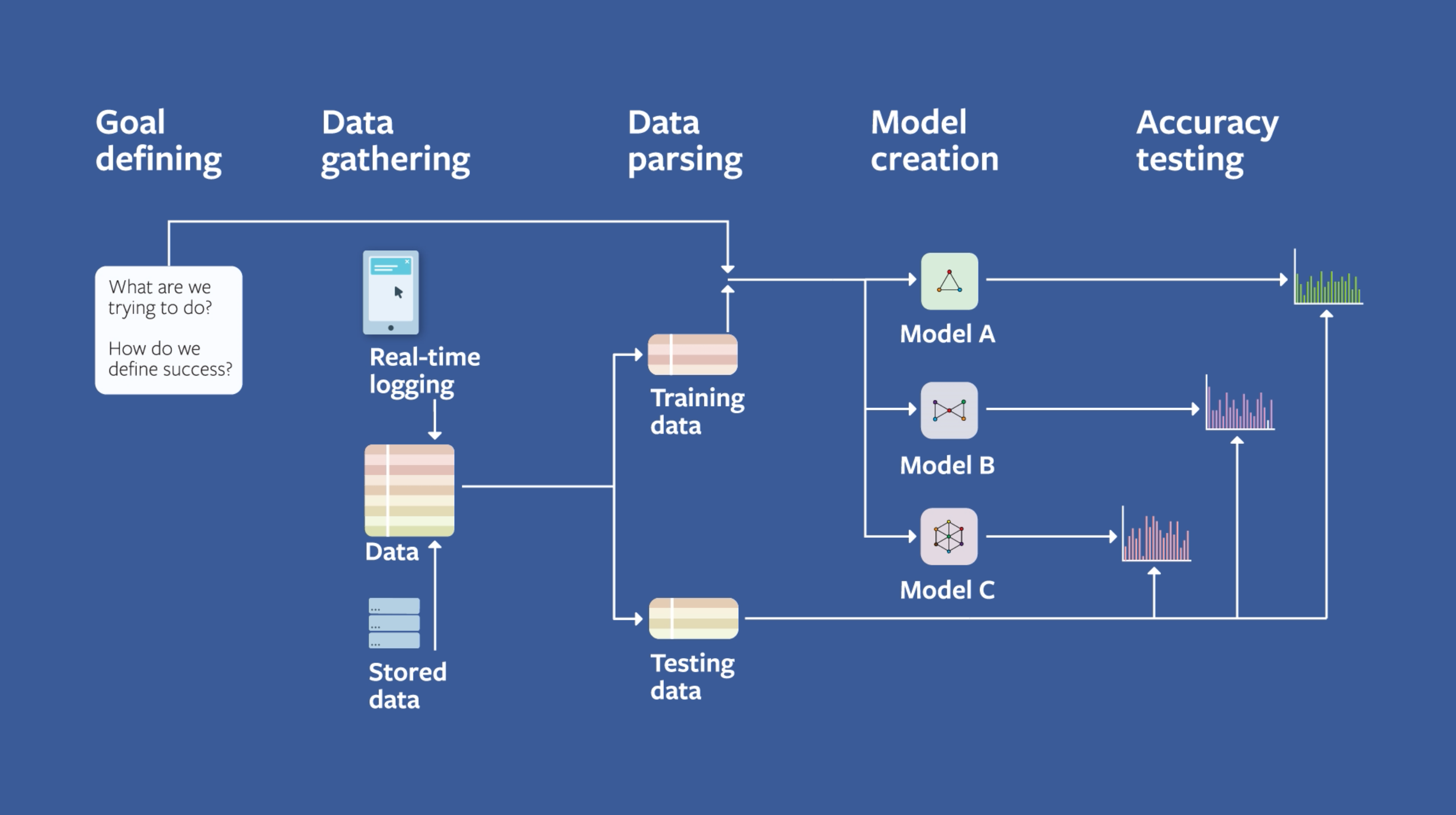
1. Định nghĩa vấn đề (Problem Definition)
Đây là công đoạn quan trọng nhất, đòi hỏi nhiều kiến thức và kinh nghiệm. Với những problem đơn giản, chỉ cần một lớp Deep Learning (hay một model) là đủ để giải quyết. Tuy nhiên với những problem phức tạp cần nhiều lớp Deep Learning để giải quyết.
Ví dụ về một problem đơn giản: nhận diện khuôn mặt

Face detection
Ví dụ về một problem phức tạp: đọc chữ trong ảnh

Scene text recognition
Một lớp hay một model Deep Learning có thể hiểu theo cách đơn giản nhất là một hộp đen: nhận dữ liệu ở đầu vào, chạy ra kết quả ở đầu ra. Tại đây chúng ta sẽ xây dựng cấu trúc của cái hộp. Sau đấy thông qua quá trình training để thay đổi tính chất bên trong.

Đút xu vào, cho ra quà, chỉnh được tỉ lệ thắng . Giống Deep Learning nhỉ ?
2. Thu thập dữ liệu (Data Gathering)
Sau khi đã định nghĩa vấn đề xong, chúng ta sẽ bắt đầu tiến hành thu thập nguồn dữ liệu tương ứng. Ví dụ như ở trong problem nhận diện khuôn mặt ở trên, chúng ta sẽ phải thu thập dữ liệu là khuôn mặt con người. Số lượng dữ liệu càng nhiều càng tốt. Ở một số nơi con số có thể lên tới hàng triệu.
Mỗi một loại dữ liệu thu thập được chúng ta sẽ đánh dấu bằng một nhãn (label) riêng. Ví dụ với label là “mèo”, data tương ứng sẽ là :

Đây là con “mèo”
Trong quá trình thu thập, việc lẫn các nhiễu (noise) vào là không thể tránh khỏi. Với cùng label là “mèo”, data như sau có thể lẫn vào

đây cũng là con “mèo”
3. Lọc dữ liệu (Data Parsing)
Quá trình training ở bước 4 yêu cầu cặp data-label phải đúng nhất có thể. Vì thế dữ liệu sau khi thu thập phải lọc qua một lần để loại bỏ nhiễu (noise), giữ cho sạch (clean) nhất có thể. Thường tiến hành bằng tay. Trong một số trường hợp đặc biệt có thể dùng một số thuật trong để phân mảnh dữ liệu để loại bỏ bớt nhiễu.
Dữ liệu sau khi lọc xong sẽ được chia ra làm 3 phần : train, validation và test. Tỉ lệ thường dùng khi chia là 7-1-2. Đến bước này chúng ta đã có 1 dataset hoàn chỉnh.
Quá trình tạo một dataset rất tốn công sức và thời gian. Thường mọi người sẽ không tạo mới mà dùng những dataset đã được công bố. Trong các tutorial tiếp theo của nhóm cũng sẽ theo xu thế này.
Training (tạo mô hình)
Sử dụng dataset ở bước 3 chúng ta sẽ tiến hành training để thay đổi tính chất của hộp đen trong bước 1.
Quá trình training là bước nhồi liên tục cặp data-label vào trong model, để thay đổi tính chất bên trong, hướng đầu ra của model đến label mong muốn. Quá trình này có thể kéo dài từ vài tiếng đến vài tuần. Để rút ngắn thời gian training, quá trình tính toán (train) sẽ được phân luồng trên nhiều GPUs.

Hình ảnh của tôi mỗi lúc training một model
Trong quá trình train, độ chính xác (accuracy) của model sẽ được kiểm tra bằng val data ở bước 3. Nếu không có vấn đề gì thì accuracy sẽ tăng dần cho đến khi đạt một ngưỡng xác định Lúc này quá trình training sẽ dừng lại.
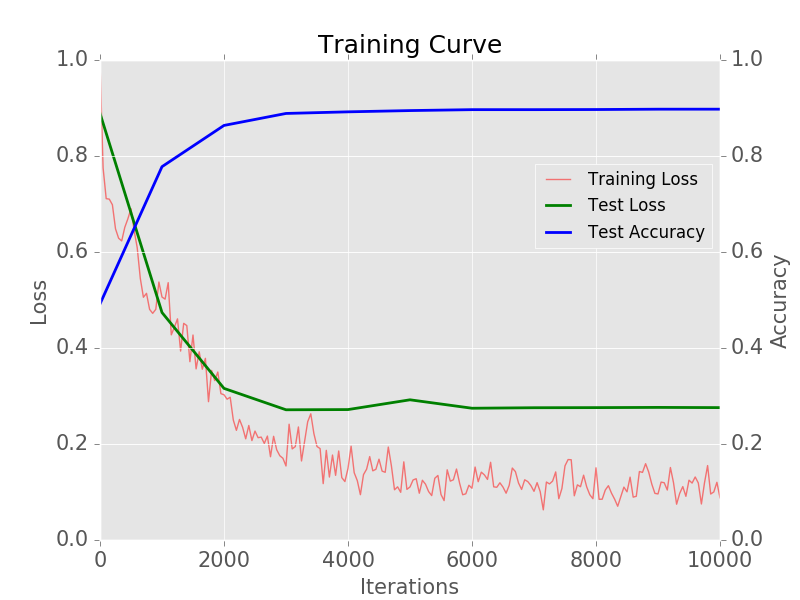 Đường màu xanh chỉ ra rằng acccuracy đã tới ngưỡng (limit)
Đường màu xanh chỉ ra rằng acccuracy đã tới ngưỡng (limit)
Testing (kiểm tra độ chính xác)
Sau khi train xong chúng ta sẽ tiến hành bước cuối cùng là testing để tính accuracy cho model. Đây là bước đơn giản nhất, chỉ cần nhồi test data vào model sau đó so sánh giữa label ở đầu ra và label vốn có của test data. Ví dụ: test data có 100, khi test thấy có 80 label là giống với label vốn có, như vậy model của chúng ta có độ chính xác là 80%.
Khi model không đạt accuracy như mong muốn thì thường sẽ dùng 2 cách sau.
- Tăng lượng data để train song song với việc lọc lại để train data gần với test data nhất.
muốn nhận diện con “mèo” này
tất nhiên không thể dùng con “mèo” này để train rồi
- Định nghĩa lại vấn đề , thay đổi model sang cấu trúc phù hợp hơn. (Vấn đề nào dùng model gì, nhóm sẽ cập nhật trong bài viết tới)
Deploying (triển khai trên sản phẩm)
Model đã train xong chúng ta có thể mang lên chạy trên các thiết bị đầu cuối. Ví dụ như các board, mạch nhúng, mobile, FPGA, …
Các thiết bị đầu cuối bị hạn chế về cấu hình phần cứng nên thường được tăng tốc bằng các framework riêng biệt. Trong những trường hợp cá biệt khi có thêm hạn chế về năng lượng tiêu thụ, model sẽ được compile trực tiếp lên trên một mạch FPGA hay một chip LSI.
 Ví dụ về một board kèm FPGA chuyên cho Deep Learning: Ultra96
Ví dụ về một board kèm FPGA chuyên cho Deep Learning: Ultra96
(Đây cũng là một bước rất khó và thú vi, nhóm sẽ cập nhật trong bài viết tới)
Kết bài
Tới đây chúng ta đã biết được một model Deep Learning được tạo ra như thế nào. Rõ ràng Deep Learning là một công cụ mạnh có thể giúp chúng ta giải quyết nhiều vấn đề hiện hữu. Tuy nhiên để công cụ này phát huy hết sức mạnh vốn có, việc tuân thủ theo quy trình kể trên là điều tiên quyết.
Vũ Gia Trường.