Lược sử về Deep Learning.
Từ ý tưởng thất bại đến nền tảng định hình thế giới hiện đại.
Mục lục:
- Giới thiệu
- Những ý niệm đầu tiên
- Khởi nguồn từ toán học … (1763 - 1935)
- … đến ý tưởng khoa học cho một chiếc máy “giống người”. (1936 - 1973)
- Phản biện và hoài nghi. (1974 - 1981)
- Trở nên thực tế hơn
- Backpropagation tái sinh. (1982 - 1988)
- Học với con người (1989 - 1994)
- Giới hạn và đình trệ. (1995 - 2001)
- Khoảng lặng
- Củng cố nền tảng. (2002 - 2006)
- Âm thầm tái xuất. (2006 - 2008)
- Chìa khóa cuối cùng. (2009 - 2011)
- Cuộc cách mạng
- Sửng sốt. (2012 - 2013)
- Thành tựu. (2014 - Nay)
- Kết bài
- Tương lai
- Những người mới
1. Giới thiệu
Ngày nay, Aritificial Intelligence (AI - trí tuệ nhân tạo) và Machine Learning (ML - máy học) hiện diện trong mọi lĩnh vực của đời sống con người, từ kinh tế, giáo dục, y khoa cho đến những công việc nhà, giải trí hoặc thậm chí là trong quân sự. Những ứng dụng nổi bật trong việc phát triển AI đến từ nhiều lĩnh vực để giải quyết nhiều vấn đề khác nhau. Nhưng những đột phá phần nhiều đến từ Deep Learning (DL - học sâu) - một mảng nhỏ đang mở rộng dần đến từng loại công việc, từ đơn giản đến phức tạp.
Tuy nhiên, không phải ai cũng biết được những nhà nghiên cứu trong ngành đã phải tốn bao nhiêu công sức, trí lực để đưa những khái niệm trừu tượng ra khỏi trang giấy, mô hình hóa nó thành những điều thú vị mà ai cũng sử dụng ngày nay. Công việc của họ cũng không phải chỉ ngắn gọn đến thế, cái mà họ cần làm là giải thích cái trừu tượng đó một cách tường minh, dựa trên những phân tích có được để xây dựng các model mới tốt hơn và quan trọng hơn hết là hiện thực hóa nó bằng ngôn ngữ lập trình. Ngày nay, công việc code một model có thể được hỗ trợ bởi các kỹ sư phần mềm, nhưng các bạn có biết, thời kỳ mà DL chỉ mới là một từ ngữ xa lạ, những nhà nghiên cứu đã phải tự làm hết, code from scratch từ những ngôn ngữ như C/C++ không?
Qua bài viết này, chúng ta hãy cùng xem lại một cách nhanh chóng quá trình phát triển của DL từ những hiểu biết đơn giản nhất cho đến thời kỳ hoàng kim như ngày hôm nay nhé!
2. Những ý niệm đầu tiên
1. Khởi nguồn từ toán học … (1763 - 1949)
Năm 1763, một bài luận về xác suất của Thomas Bayes được xuất bản 2 năm sau khi ông qua đời, lúc đó í tai quan tâm đến nó. Gần nửa thế kỷ sau, vào năm 1812 nó được nhà toán học Laplace hợp thức hóa thành lý thuyết xác suất mà ngày nay chúng ta gọi là Định lý Bayes, cốt lõi của mạng Bayes hay Belief Network, là một trong những cấu trúc đóng góp lớn đến thành công của DL ngày nay (Deep Belief Network).
Năm 1770, máy mô phỏng AI đầu tiên được giới thiệu, người Thổ Nhĩ Kỳ đã lừa Napoleon rằng một chiếc máy của họ có thể chơi cờ vua. Năm 1857, họ tiết lộ rằng chiếc máy đó đơn giản chỉ là có một người ngồi bên trong. Lúc đó, chả ai biết rằng 140 năm sau, một AI thực sự đánh bại đại kiện tướng Kasparov bằng những nước đi mà nó tạo ra.
Năm 1805, lý thuyết về Least Squares ra đời, thời đó được sử dụng trong thiên văn và trắc địa, không ai biết được ngày nay nó là hàm loss cơ bản nhất của Artificial Neural Network (ANN).
2. … đến ý tưởng khoa học cho một chiếc máy “giống người”. (1936 - 1973)
Năm 1936, lấy cảm hứng từ việc con người thực hiện các công việc bình thường như thế nào, Alan Turing định hình nên ý niệm của ông về một Universal Machine (máy toàn năng). Sau nhiều năm nghiên cứu, ông công bố bài báo của mình dưới dạng một bài luận cùng với một ý tưởng về bài kiểm tra cho một chiếc máy mô phỏng con người: Turing Test. Có lẽ, ông không biết rằng, 60 năm sau khi ông mất, những AI đã bắt đầu passed qua bài Test.
Năm 1957, ý tưởng về Perceptron, dựa trên cấu trúc tế bào thần kinh trong não bộ con người, lần đầu tiên được công bố, khi đó nó bao trùm cả truyền thông về một tương lai tươi sáng sắp tới gần của AI. Cùng với đó, 13 năm sau, một khái niệm bổ sung được phát minh bởi Seppo Linnainmaa, gọi là Auto Differentation (đạo hàm tự động), là hình thái đầu tiên của lý thuyết mà chúng ta gọi là Backpropagation ngày nay.
Các thuật toán cơ bản khác được phát minh như Nearest Neighbor năm 1967 hay TF-IDF năm 1972 chủ yếu liên quan đến xác suất thống kê, nhưng đây là 2 thuật toán quan trọng nhất, lần lượt tạo nên 2 nhánh lớn của DL hiện nay: Computer Vision (CV) & Pattern Recognition và Natural Language Processing (NLP) & Speech Recognition.
3. Phản biện và hoài nghi. (1974 - 1981)
Năm 1969, cuốn sách Perceptrons được xuất bản, giới thiệu cho độc giả về những giới hạn của Perceptron, trong đó nhất mạnh việc Perceptron không thể học cách biểu diễn hàm XOR (ngày nay chúng ta đều biết nó đã trở nên đơn giản). Hơn nữa, họ còn chứng minh rằng Perceptron là không thể học các hàm phi tuyến được vì giá trị của nó chỉ dựa trên bộ dữ liệu tuyến tính.
Năm 1973, Perceptron/ANNs nhường chỗ cho các thuật toán tiến hóa (Genetic Algorithm), cộng đồng phát triển AI rơi vào mùa đông đầu tiên.
3. Trở nên thực tế hơn
1. Backpropagation tái sinh. (1982 - 1988)
10 năm sau khi TF-IDF ra đời, một cấu trúc mới phát triển hơn nữa đã báo hiệu sự trở lại ANN sau một mùa đông dài lạnh giá, Recurrent Neural Network (RNN) là công cụ đa năng để xử lý những dãy/chuỗi mà chúng ta vẫn dùng rộng rãi cho đến tận ngày nay.
Ngày nay chúng ta đều hiểu rằng, multilayer-perceptron (MLP – mạng Perceptron đa lớp), thậm chí chỉ cần 1 hidden layer (lớp ẩn) cũng đủ để xấp xỉ mọi hàm số. Lý thuyết đó gọi là Universal approximation theorem (UAT).
Đó là vào năm 1986, một sinh viên postdoc trong ngành khoa học nhận thức của UC San Diego, Geoff Hinton, cháu 4 đời của George Boole (người sáng tạo nên lý thuyết logic ngày nay, kiểu dữ liệu bool/boolean là để tưởng nhớ ông), Hinton bất chấp những chỉ trích về Perceptron của các tác giả đương thời, cùng với những người bạn của mình công bố một bài báo mà đã làm hồi sinh Perceptrons. Bằng việc tổng quát hóa AutoDiff của Seppo thành một thuật toán ngày nay chúng ta đều biết đến: Backpropagation. Việc chồng nhiều lớp Perceptrons đã giúp ANN vượt qua khuyết điểm của Perceptrons, điều mà trước đó chưa ai thực hiện.
Không chỉ vậy, cùng thời điểm đó, UAT ra đời, thúc đẩy cuộc bùng nổ về nghiên cứu ANN. Nổi trội nhất trong đó là việc phát minh ra Convolutional Neural Nets (CNN): một học trò của Hinton, cũng là nhân vật quan trọng trong sự phát triển của DL, Yann LeCun đã tạo ra LeNet5, được xem là CNN đầu tiên được hiện thực hóa. Để làm được điều đó, LeCun đã tạo ra một datasets riêng mà chúng ta vẫn dùng đến ngày nay, bộ số viết tay MNIST, năm 2017 đã mở rộng thành EMNIST.
2. Học với con người (1989 - 1994)
Con người chúng ta học không phải theo cách của ANN, mỗi người đều vừa học vừa làm, có khi còn tự học. AI là mô phỏng lại khả năng của con người, vậy tại sao chúng cũng không làm như vậy?
Và thế là Reinforcement Learning (RL – học tăng cường) được phát minh ra năm 1989. Thực tế, đó là sự mô mình hóa bằng toán học quá trình học tập của con người, một điều không hề đơn giản. Q-learning chính là kết quả của nhiều năm nghiên cứu để đưa RL trở nên thực tế hơn, đơn giản hơn của Christopher Watkins. Đó còn là một dấu hiệu cho tương lai của những AI chơi game đang đến gần.
3. Giới hạn và đình trệ. (1995 - 2001)
Tuy phát triển vũ bão là thế, nhưng cuối cùng, những sự đầu tư đã không nhận được những thành quả đáng tin cậy, đơn giản là những mô hình được tạo ra chỉ ở mức cục bộ, không thể áp dụng cho những bài toán lớn được. Do đó cả cộng đồng phát triển AI quay trở lại với những phương pháp nhanh chóng, chính xác hơn, chẳng hạn như Support Vector Machine (SVM). Và thế là ANN lại rời bỏ sàn đấu, một lần nữa DL rơi vào mùa đông thứ hai.
Trong suốt quãng thời gian đó, những công cụ AI khác dần phát triển, nổi bật nhất chính là Monte Carlo Tree Search (MCTS), cốt lõi của DeepBlue, AI đầu tiên đánh bại đại kiện tướng Garray Kasparov năm 1997. Tuy gọi là DeepBlue như thế nhưng thực ra là để thể hiện khả năng tìm kiếm nhanh chóng, độ sâu cao của MCTS trong đó chứ không liên quan đến DL.
Với sự ra đời của Long-Short Term Memory (LSTM) năm 1997, nền tảng lý thuyết đã gần đạt đến mức đầy đủ như chúng ta đang thấy ngày nay, để tạo nên những ứng dụng lớn lao của ANN. Tuy nhiên, chỉ còn một vài thứ vô cùng quan trọng khác còn thiếu khiến cho khả năng của ANN bị giới hạn. Có thể nói đó là lý thuyết đi trước thời đại.
4. Khoảng lặng
1. Củng cố nền tảng. (2002 - 2006)
Còn rất nhiều việc khác ngoài phát triển lý thuyết để tạo nên sự phát triển của DL mà chúng ta thấy ngày nay. Đây là quãng thời gian mà mọi thứ bắt đầu được chuẩn bị.
Bây giờ, chúng ta đều biết, để xử lý những vấn đề lớn một cách nhanh chóng thì hiển nhiên phải sử dụng những công cụ chất lượng cao, phải chứ? Không thể nào chúng ta có thể vẽ chính xác bản đồ của Trái Đất chỉ với bút chì và giấy bình thường được. Điều đó là tương tự với DL.
Trước hết, chúng ta cần một framework để những nhà nghiên cứu nhanh chóng thử nghiệm các ý tưởng của họ mà không phải quá tập trung vào các vấn đề liên quan đến kỹ thuật phần mềm (software engineering). Vậy là framework ML đầu tiên ra đời: Torch. Đây là framework viết bằng Lua interface với back-end là C, những vấn đề mà nó gặp phải đã trở thành những bài học quý báu cho các framework về sau như Tensorflow hay PyTorch.
Tuy nhiên, việc tạo ra các model tốt và việc model đó hoạt động tốt là hai thứ hoàn toàn khác nhau. Những nhà nghiên cứu muốn nhanh chóng thử nghiệm model của họ trên thực tế, họ cần phải có một công cụ tính toán hiệu quả, nhanh chóng. Đó là sự tăng tốc đến từ phần cứng, trong suốt quá trình phát triển thầm lặng của DL, ít ai hiểu rõ tầm quan trọng của phần cứng đối với hiệu quả thực tế của model. Bước ngoặt được tạo ra khi NVidia thiết kế thành công kiến trúc CUDA năm 2006, lúc đó họ chưa biết rằng hiệu quả từ kiến trúc này to lớn như thế nào. 10 năm sau, dòng GPU chuyên biệt hỗ trợ DL của NVidia chính thức ra mắt – Volta.
Cùng năm đó, giải thưởng Netflix được công bố cho những ai thiết kế Recommendation System (hệ thống đề xuất cho người dùng) với độ chính xác cao hơn họ 10%. Tuy cuộc thi đã kết thúc khi giải thưởng được trao năm 2009 nhưng nó đã làm tiền đề cho các cuộc thi AI quan trọng sau này, trong đó có Kaggle, nơi mà các team phát triển AI tranh đấu với nhau hiện nay.
2. Âm thầm tái xuất. (2006 - 2008)
Trong suốt những năm đó, Hinton vẫn dày công tìm cách đưa ANN đến với thế giới thực. Với những thành quả mình, bao gồm sự xuất hiện lần đầu của khái niệm Unsupervised Pretraining (tiền huấn luyện không giám sát) và giới thiệu đến giới khoa học Deep Belief Networks dựa trên mạng Bayes, ông tuyên bố mình hiểu cách mà não bộ hoạt động. Với những kết quả nghiên cứu của ông, người ta đã có thể train những ANN sâu hơn, rộng hơn.
Vậy là kể từ năm đó, DL trở thành một nhánh riêng biệt, tách khỏi ANN trong ML:
Deep Learning… moving beyond shallow machine learning since 2006! (deeplearning.net)
3. Chìa khóa cuối cùng. (2009 - 2011)
Tuy Hinton đã nghiên cứu một cách sâu sắc, chi tiết là thế nhưng cuối cùng, những thành quả thực tế thu được vẫn chưa đáng kể là bao. Lúc đó, không ai biết tại sao. Đấy là lúc mà người ta luôn cho rằng chỉ cần có model tốt thì dù dataset có ít đến đâu cũng có thể tạo ra được kết quả thực tế thật tốt.
Chỉ có vài người vượt qua những định kiến đó, trong số đó có Fei Fei Li và các học trò của cô. Trải qua bao nhiêu khó khăn, chịu đựng chỉ trích trong suốt 2 năm rưỡi, họ đã tạo nên một dataset to lớn với hàng triệu bức ảnh và hơn 1000 nhãn vào năm 2009, vượt xa dataset nổi tiếng đương thời của PASCAL VOC. Lúc đầu, ImageNet chỉ là dataset được dùng cho training, nhưng năm 2010, họ biến nó thành một cuộc thi: ILSVRC. Điều mà sau này nhiều người cho là tiên phong cho khởi đầu của một kỷ nguyên mới, không chỉ trong ngành AI mà là cả định nghĩa về xã hội hiện đại.
Vậy là cuối cùng, mọi công cụ chuẩn bị đã hoàn tất. Những dấu mốc sắp tới là bắt đầu của thời đại mà ngày nay chúng ta gọi là Cách mạng 4.0.
5. Cuộc cách mạng ]
1. Sửng sốt. (2012 - 2013)
Trong suốt 2 năm cuộc thi ILSVRC được tổ chức, hàng trăm AI đã được submit, tất cả đều là những sự kết hợp của các công cụ trích lọc features được thực hiện bằng tay (e.g. SIFT, SURF, FAST, BRISK, AKAZE, …) và SVM để classify (phân loại) các bức ảnh. Năm 2011, AI tốt nhất vẫn có top-5 error là 25.77%, cho thấy khả năng của AI vẫn là chưa đáng tin cậy để ứng dụng trong thực tế.
Năm 2012, Alex Krizhevsky, Ilya Sutskever, và người hướng dẫn của họ lại là Hinton, submit một model và làm bất ngờ không chỉ giới nghiên cứu ML mà cả những người làm việc trong ngành AI, và sau này là cả thế giới khi đạt top-5 error là 16%. Đây là lần đầu tiên một model ANN đạt kết quả state-of-the-art.
Họ tiết lộ rằng đây là một model CNN, là Deep CNN đầu tiên mà ngày nay chúng ta biết đến như là AlexNet. Trong model này, họ giới thiệu đến công chúng những kỹ thuật mà chưa ai từng nghĩ đến mà ngày nay chúng ta đã thấy rất quen thuộc: ReLU activation và DropConnect/Dropout. Hơn nữa, model được train trên dataset của chính ImageNet năm 2011, với sự tăng tốc của GPU hỗ trợ bởi CUDA. Đây là những sự kết hợp chưa ai từng trực tiếp thử nghiệm.
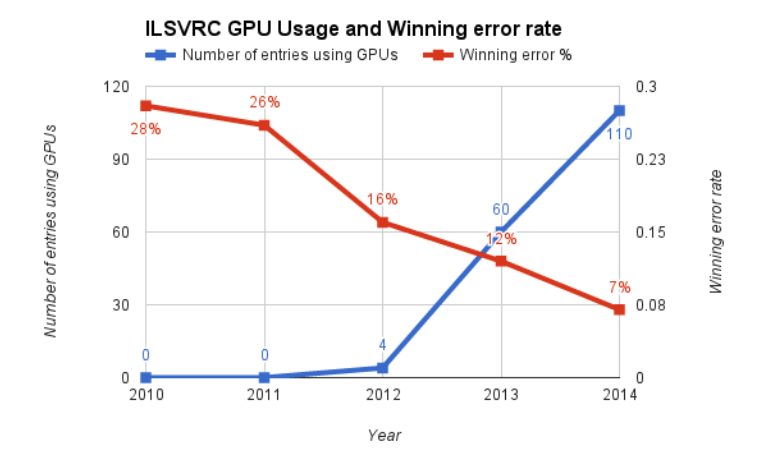 Kết quả ILSVRC qua từng năm
Kết quả ILSVRC qua từng năm
Sau khi kết quả ILSVRC được công bố, các nhà nghiên cứu ANN bắt đầu cân nhắc DL như là một lựa chọn thay thế cho các phương thức truyền thống. Sự lan tỏa bắt đầu trở nên phổ biến khi một DL model khác là Clarifai đạt 11.2% trong ILSVRC 2013. Điều này thúc đẩy nhiều nhà nghiên cứu chuyển hẳn sang DL. Từ đó, các model state-of-the-art mỗi năm trên ImageNet đều là các DL model, với độ sâu ngày một tăng.
Độ sâu các state-of-the-art ANN qua từng năm
2012 là năm mà sự quan tâm được chuyển sang cho DL, cho thấy sự khởi đầu để DL bao trùm mọi mặt của cuộc sống con người. Mặc dù năm 2017 là năm cuối cùng của ILSVRC nhưng những di sản mà cuộc thi này để lại là không thể bác bỏ được.
2. Thành tựu. (2014 - Nay)
Kể từ năm 2013, không chỉ các nhà nghiên cứu mà cả các công ty công nghệ cũng bắt đầu chú ý đến DL. Trước năm 2009, Google phát triển một nền tảng DL (mặc dù lúc đó chưa được chú ý nhiều) gọi là DistBelief, dẫn đầu bởi chính Hinton, đóng vai trò quan trọng trong việc giảm thiểu lỗi của các hệ thống ML. Kể từ sau sự kiện 2012, Google đẩy mạnh đầu tư vào mảng này, chỉ định thêm các nhà khoa học máy tính để cải tiến nền tảng, cả về lý thuyết lẫn cấu trúc của source code. Cuối cùng, nó trở nên mạnh mẽ, nhanh chóng và gọn gàng hơn trước khi được đổi tên thành Tensorflow vào ngày 9/11/2015 dưới dạng open-source.
Tiếp theo sau đó, những DL framework khác lần lượt ra đời, phát triển, thậm chí chấm dứt vì sự cạnh tranh khốc liệt.
Năm 2014, Facebook công bố DeepFace của họ, công cụ mà cho đến tận bây giờ chúng ta vẫn dùng để tag lên hình ảnh của mình. Với 97.35% độ chính xác, DeepFace vượt mặt những đối thủ của nó. Thực tế thì nó đã gần đạt được độ chính xác của con người dù con số 2.65% error không phải là nhỏ. Tuy vậy, đây vẫn là một dấu hiệu báo trước ngày mà những hệ thống DL vượt qua khả năng của con người đã không còn xa: AlphaGo (Lee ver.) đánh bại đại kiện tướng cờ vây Lee Sedol 4-1 vào năm 2016, cho thấy một bước tiến to lớn trong gần 20 năm từ khi DeepBlue đánh bại Kasparov (không gian tìm kiếm và luật chơi cờ vây khó hơn cờ vua rất nhiều).
Tuy nhiên, trong năm 2017. DL liên tục gửi những bất ngờ đến với cả thế giới: OpenAI bot đánh bại Dendi, người chơi Dota 2 chuyên nghiệp tại The International 2017. Đáng chú ý hơn nữa AlphaGo (Zero ver.) đánh bại phiên bản trước đó (Lee ver.) mà không cần sự hướng dẫn của con người, chỉ tự chơi với chính nó (Lee ver. phải học từ các lượt chơi của con người, sau đó mới tự học). Và AlphaZero, được tổng quát hóa hơn AlphaGo, tự tìm ra cách chơi cờ vua và cờ shogi, tự tạo ra những nước đi của chính nó và không cần đến con người can thiệp vào quá trình học, nó đánh bại phiên bản cao nhất của bot chơi cờ vua mà hầu như các bạn chơi đều biết – StockFish 8 với tỉ số 28 – 0 (72 trận khác hòa).
Tại sao những AI chơi game như vậy lại được liệt kê trong lược sử của DL, chẳng phải nó chỉ đơn giản dùng MCTS thôi ư? Đối với Dota 2, đây là trò chơi online, muốn một con bot đánh được thì nó cần phải nhìn vào screen với map, do đó CV đóng một vai trò rất quan trọng. Đối với AlphaGo/Zero cũng tương tự, không chỉ mã hóa bàn cờ bằng CV, sự kết hợp với Guided MCTS giúp nó khai phá dữ liệu trò chơi sâu hơn, các kỹ thuật và khả năng lượng giá của nó được mã hóa bởi CNN, nước đi được tạo ra bởi Generative Adversarial Network (GAN) để định hướng cho MCTS.
5. Kết bài ]
1. Tương lai
Trước sự phát triển vượt bậc đó, DL hứa hẹn sẽ mang lại những thành quả bất ngờ và những bước tiến của nó sẽ ảnh hưởng sâu rộng hơn đến cuộc sống của mỗi người trong xã hội hiện đại. DL mang đến một thời đại mới với cuộc cách mạng cũng nó cũng như đặt ra các thách thức cho mỗi người để không bị thay thế.
Nhiều người sẽ cho rằng, trong tương lai gần, các AI sẽ có thể mô phỏng thật giống con người. Thực tế cho thấy đó không phải là điều không thể. Nhưng có lẽ ngày đó sẽ còn xa lắm, nếu như chúng ta phát triển DL theo cách như hiện nay?
Người đứng đầu cơ quan phát triển AI của Facebook, LeCun cho rằng DL đang dần trở thành một thứ như Giả kim thuật, với việc các model là một blackbox, chúng ta không thể biết chúng đã học được những gì từ dataset, những thứ chúng học có đúng không, hay thậm chí những điều chúng ta biết về chúng có chính xác không?
Nguyên nhân cho việc này là những nghiên cứu phát triển theo cấp số mũ, không có định hình được cụ thể những nguyên lý khác ngoài việc tạo ra model hay dataset (e.g. việc tại sao một số model converge được trong khi một số thì không vẫn chưa có lời giải, việc giải nghĩa các weight của ANN vẫn còn là một bí ẩn, …).
2. Những người mới
Những nhà nghiên cứu đã rất cố gắng trong việc tạo ra model bằng những nghiên cứu trước đó, các phân tích cụ thể cho vài trò của từng thành phần trong ANN và sử dụng các dataset phù hợp để đưa model đạt accuracy tốt nhất. Đó là cả một quá trình để có thể tạo ra được một model chấp nhận được, không phải dễ dàng để có được Ph.D hay Postdoc trong ngành DL.
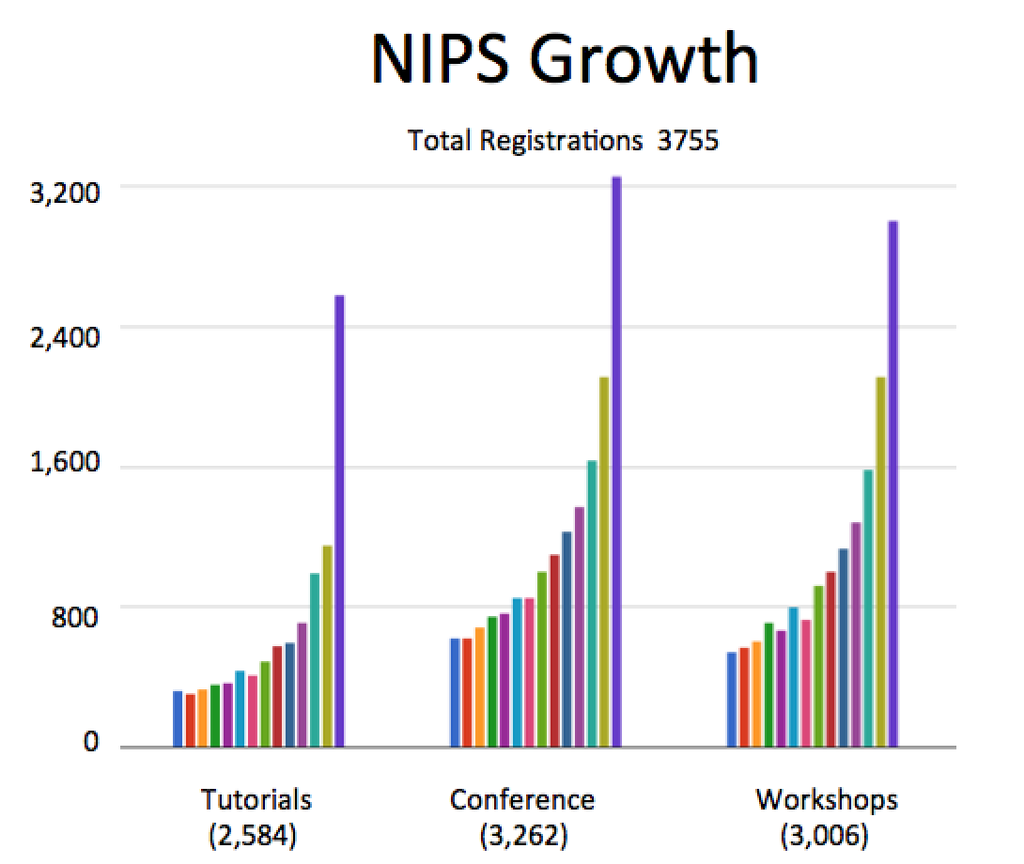 Số lượng người tham gia Neural Information Processing Systems (NIPS) – hội thảo khoa học chuyên về ML và computational neuroscience tăng nhanh chóng.
Số lượng người tham gia Neural Information Processing Systems (NIPS) – hội thảo khoa học chuyên về ML và computational neuroscience tăng nhanh chóng.
Việc học cũng vậy, những người mới tham gia vào có thể theo học các course được các Professors đầu ngành hoặc các kỹ sư chuyên ngành tại các tập đoàn lớn. Để nắm rõ được DL, bạn cần phải có một nền tảng toán học tương đối và tư duy lập trình căn bản, nhất là niềm đam mê với ngành, nếu không, những sự khó khăn sẽ khiến cho bạn từ bỏ sớm.
Dĩ nhiên, học hay nghiên cứu đều cần rất nhiều sức lực, không chỉ đơn giản là clone code trên github về rồi download pretrained model hay train.py một chút và sau đó kết hợp với mấy model khác thành một ensemble, đem đi evaluate có accuracy cao là được. Bản thân model state-of-the-art, ví dụ như ShakeDrop+AutoAugment trên MNIST đã là một ensemble và còn được train bởi mạng AutoAugment khiến cho dữ liệu của nó tăng rất nhiều lần, tăng độ chính xác của ShakeDrop (hiệu quả của Data Augmentation).
References:
Time line of Machine Learnig - Wikipedia
Time line of Artificial Intelligence
Google’s blog on cloud.google.com
Hải Đăng