YOLO: Real-Time Object Detection (phần 1)
Mục lục:
1. Giới thiệu
2. Ý tưởng của YOLO
YOLO - You only look once. Cái tên của thuật toán nói rõ lên đặc điểm nổi bật của nó. YOLO chỉ dùng một mạng CNN và áp dụng lên ảnh input một lần duy nhất để học các đặc trưng trên ảnh. Nó giống như chúng ta nhìn toàn thể bức ảnh và bắt đầu dò tìm các đối tượng trong nó. Vì thế nên thời gian thực thi thuật toán của YOLO là rất nhanh (171 khung ảnh trên một giây với cấu trúc mạng Darknet-19) và có thể áp dụng cho các bài toán nhận dạng đối tượng trên video và các ứng dụng theo thời gian thực. Về độ chính xác thì YOLO không được đánh giá ngang hàng so với các phương pháp hiện nay như Faster RCNN hay RetinaNet. Tuy nhiên, nhờ vào ý tưởng đơn giản, YOLO vẫn là một thuật toán được ứng dụng nhiều trong các bài toán nhận dạng đối tượng trong ảnh cần thời gian thực hiện nhanh mà không cần độ chính xác quá cao hoặc các đối tượng cần nhận dạng không quá khó.
YOLO mô hình bài toán nhận dạng đối tượng thành bài toán hồi quy trong miền không gian các rời rạc của các bounding box. Thuật toán chia nhỏ ảnh input thành lưới gồm S x S cell. Nếu tâm của đối tượng cần xác định rơi vào một cell nào đó thì cell đó sẽ chịu trách nhiệm xác định đối tượng đó và bounding box của nó. Thuật toán sử dụng một mạng neural đơn với đặc trưng có được từ các feature map của các lớp convolution để dự đoán B bounding box ở mỗi cell và xác suất loại đối tượng nào đang được chứa bên trong. Sau cùng, ta sẽ có rất nhiều bounding box được thuật toán đưa ra với kích thước khác nhau. Sử dụng thuật toán Non-Maxima Suppresstion (NMS) ta có thể loại được các hầu hết các bounding box là miền bao của cùng một đối tượng, có chỉ số score thấp và giữ lại các bounding box có score cao.
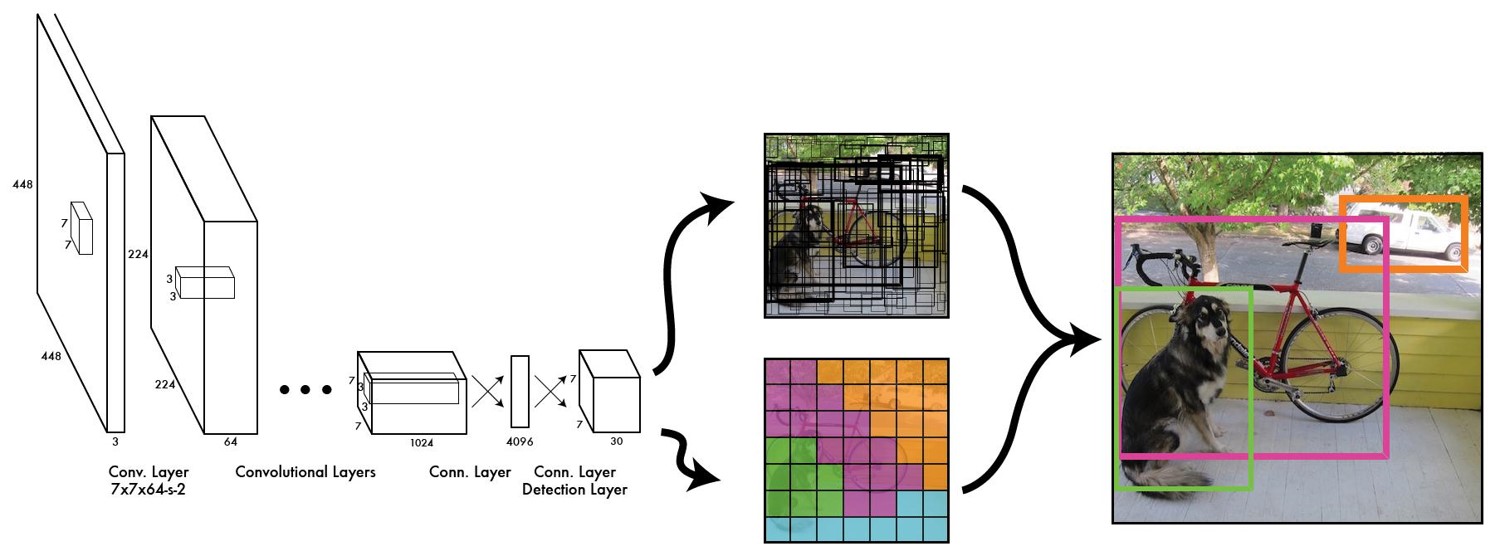
3. Chi tiết thuật toán
Ở bài viết này, ta tạm thời chưa phân tích bộ trích đặc trưng (feature extractor) mà xoáy vào ý tưởng thuật toán YOLO về cách xác định các bounding box.
Tại mỗi cell sẽ có trách nhiệm xác định B bounding box có kích thước và tỉ lệ khác nhau để bắt lấy các đối tượng cần xác định trong hình. Sau khi thuật toán được thực thi, mỗi bounding box sẽ được gán những confident rate. Chỉ số này phản ánh cho ta biết box có đang chứa một đối tượng nào hay không, với xác suất cụ thể. Thông thường, trong quá trình training, confident rate thường được thiết lập như sau:
Pr(Object): Xác suất có một đối tượng được chứa bên trong bounding box đó. $IOU_{pred}^{truth}$ (IOU - Intersection over union) là tỉ lệ trùng khớp của bounding box được dự đoán với groundtruth của một đối tượng (được miêu tả ở hình 2). Nếu box không chứa đối tượng nào, ta mong muốn rằng giá trị confident rate sẽ bằng 0. Trong thực tế, ta không có được groundtruth của vật thể nên trong quá trình testing chỉ số confident rate sẽ chỉ còn là xác suất Pr(Object).
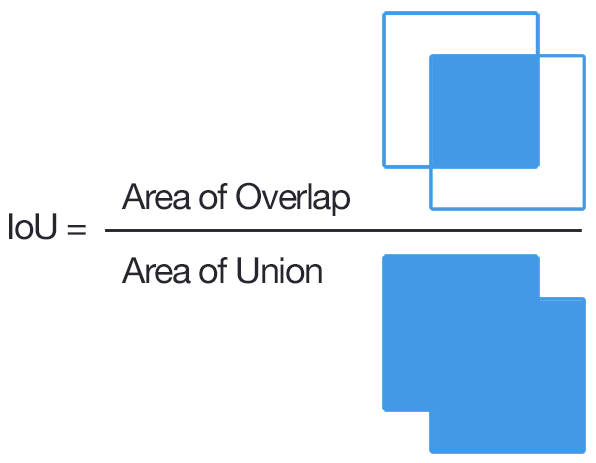
Hình 2. Một biểu diễn công thức IOU.
Ở mỗi cell, để xác định được vị trí của các bounding box, thuật toán phải tính được được 5 giá trị tương ứng cho mỗi box: $b_x,b_y,b_w,b_h$ và confident rate. Giá trị $(b_x,b_y)$ là tọa độ của tâm điểm của box, $b_h$ và $b_w$ lần lượt là chiều cao và chiều rộng của box. 4 giá trị $b_x,b_y,b_w$ và $b_h$ sẽ lần lượt được tính thông qua $t_x,t_y,t_w$ và $t_h$ theo công thức sau:
Với $p_w$ và $p_h$ là kích thước box được định sẵn ban đầu (anchor) và có tỉ lệ tương ứng với kích thước ảnh input. $(c_x,x_y)$ là tọa độ trên trái của cell đang xét. Các tham số $t_x,t_y,t_w$ và $t_h$ được học trong quá trình training. Ta có thể thấy rằng, tọa độ và kích thước của mỗi bounding box sẽ được xác định dựa trên tọa độ của cell đang xét và kích thước của anchor mặc định ban đầu thông qua giá trị từ một hàm phi tuyến của các tham số t ($α(t)$ và $e^t$) Hình 3 minh họa cho mối liên hệ giữa các tham số với nhau. Ở YOLO phiên bản 2 trở đi, các kích thước của anchor được thiết lập dựa trên kích thước của các đối tượng trong tập huấn luyện bằng thuật toán gom nhóm k-means.
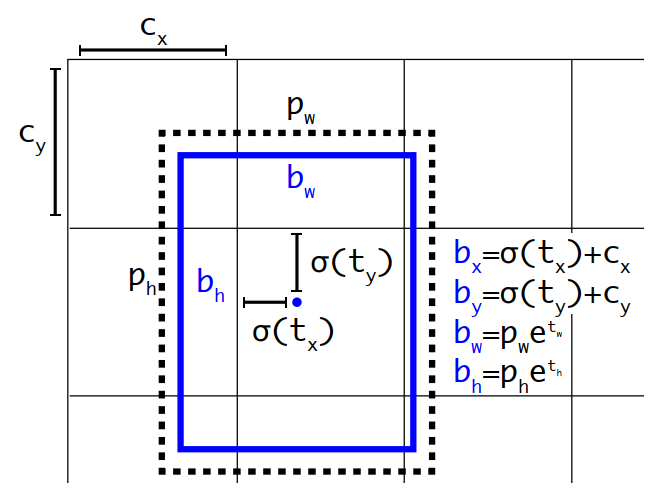
Hình 3. Minh họa cho mối liên hệ giữa các tham số.
| Ngoài giá trị confident rate đã được nói đến ở trên, thuật toán cần xác định cụ thể đối tượng nào đang được chứa trong từng box bằng cách tính xác suất có điều kiện $P(Class_i | Object)$. Sau cùng, ta tổng hợp xác suất này với confident rate được nêu trên để tạo thành confident scores cho từng loại đối tượng (class). |
Tổng kết lại, network được thiết kế để trả ra một ma trận khối 3 chiều (tensor) có $S \times S \times (B \times 5+C)$ giá trị, với $C$ là số lượng class của bài toán. Sau khi có được output này, ta sẽ có rất nhiều bounding box được đưa ra bởi mỗi cell. Nhưng hầu hết trong số chúng đều có confident scores thấp hoặc cùng bao phủ một đối tượng trong ảnh. Do vậy ta cần phải loại bỏ hết các miền bao “dư thừa” này càng nhiều càng tốt. Các bước để chọn các bounding box của các đối tượng trong ảnh và loại các box dư thừa sẽ được trình bày ở phần dưới đây.
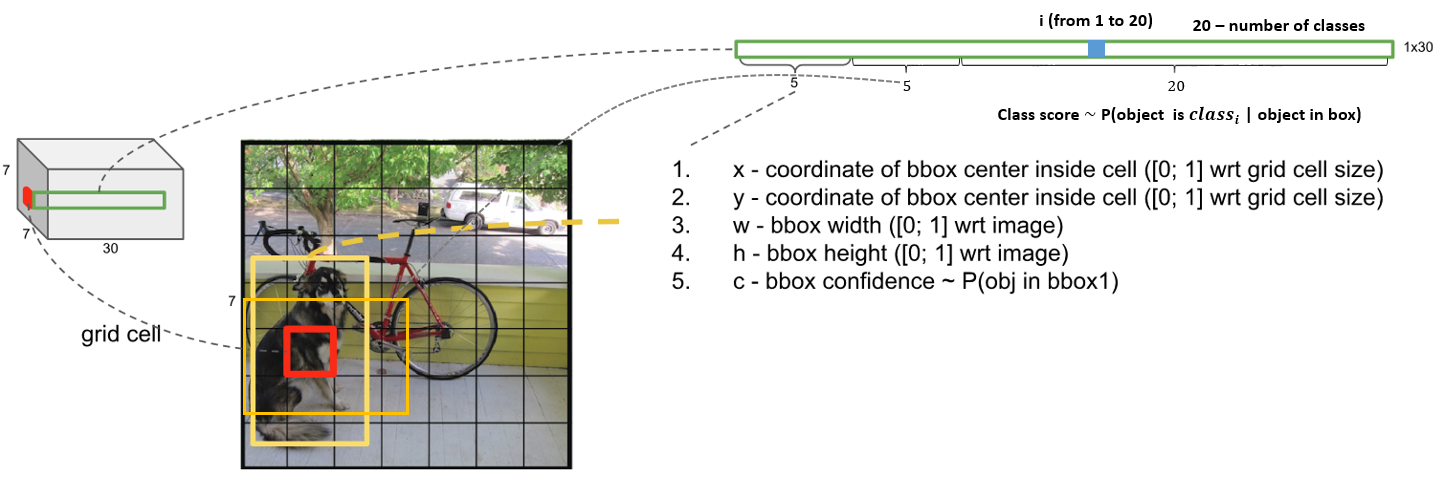
Để dễ dàng mô tả quá trình chọn các bounding box, ta giả sử số lượng bounding box mà mỗi cell cần xác định là bằng 2 $(B=2)$, số lượng class là 20 $(C=20)$ và $S = 7$. Hình 4 mô tả chi tiết các giá trị được lưu trong tensor trả ra từ mạng CNN, bao gồm các tham số của 2 bounding box và các xác suất có điều kiện $P(Class_i |Object)$ đã được đề cập ở trên.
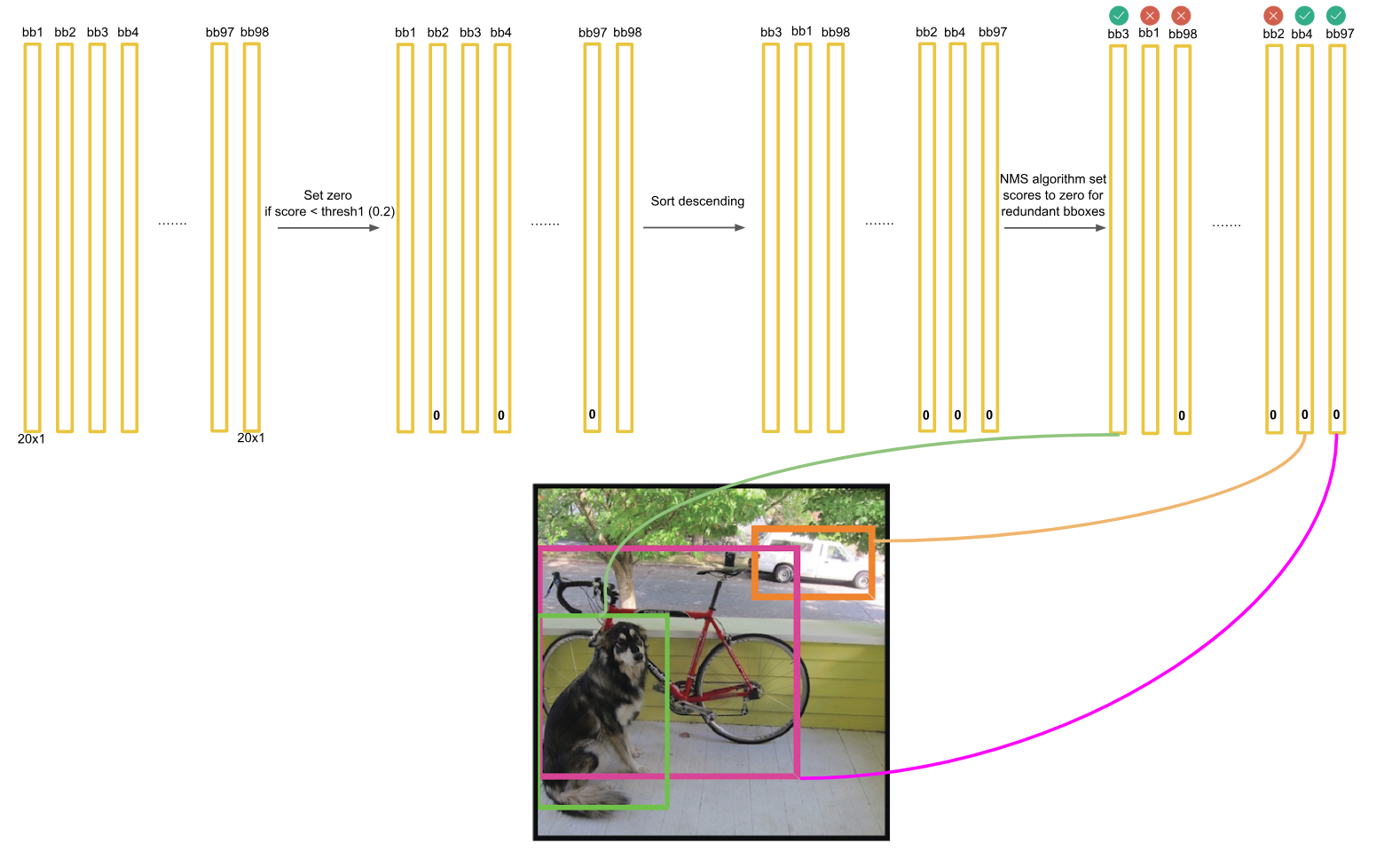
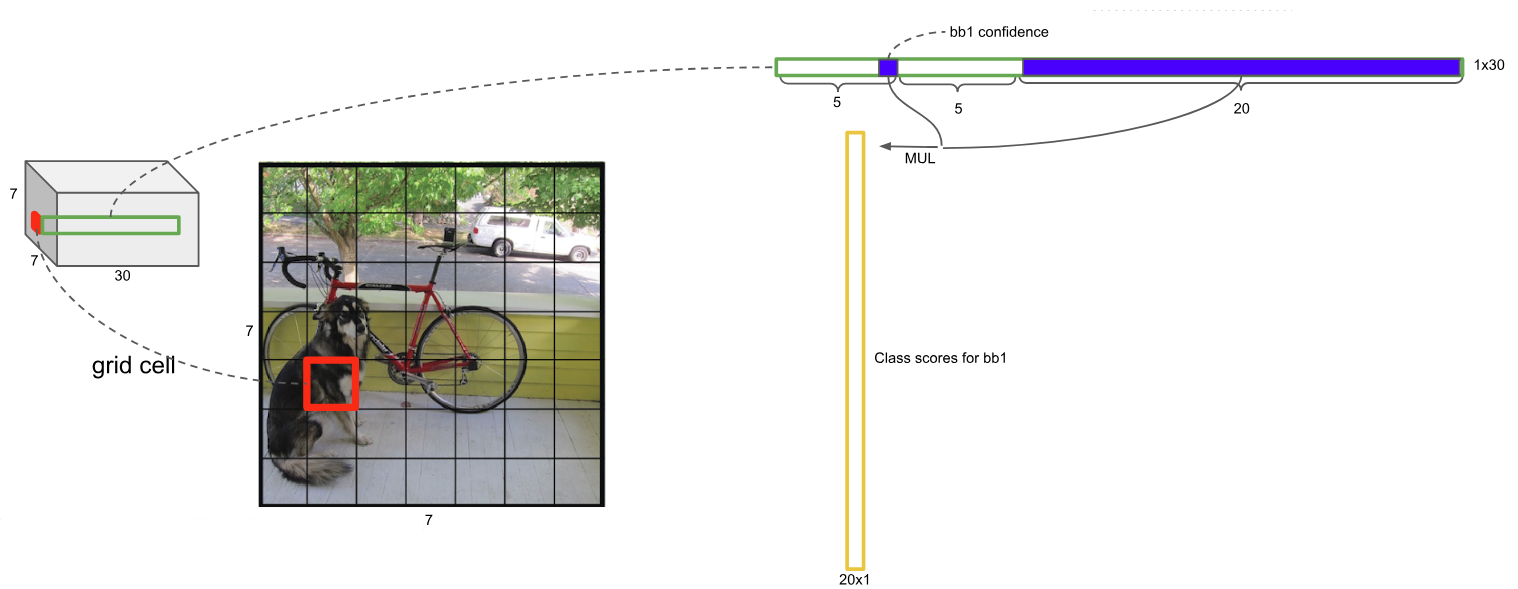
| Đầu tiên, ta cần tính được vector của confident scores cho mỗi bounding box bằng tích confident rate của mỗi bounding box và vector xác suất P(Class_i | Object) (được mô tả ở hình 5). Sau khi lần lượt tính được các vector của confident scores cho mỗi bounding box, ta có được một mảng các vector được mô tả ở hình 6. |
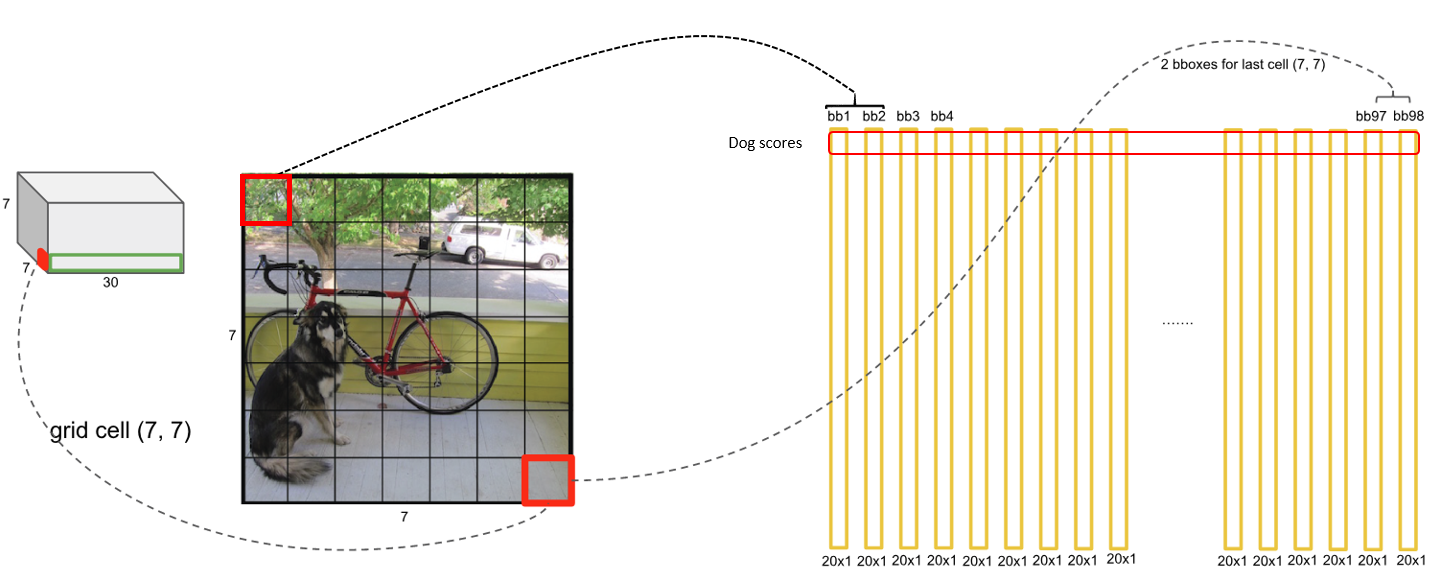
Kế tiếp, sau khi có được toàn bộ confident scores, ta bắt tay vào xét từng class để xem có đối tượng nào thuộc class này tồn tại trong ảnh đang xét hay không. Với mỗi class, ta lần lượt lấy những score tương ứng của class đó ở từng bounding box. Đồng thời ta loại bỏ những trường hợp có score thấp hơn một ngưỡng nhất định nào đó bằng cách gán 0 cho score đó. Mảng chứa score này sẽ được sắp xếp theo chiều giảm dần để có thể dễ dàng áp dụng thuật toán NMS.
Ý tưởng của NMS rất đơn giản như sau:
Bước 1: Ta lấy bounding box có score của class đang xét cao nhất làm chuẩn và cho rằng đây chính là bounding box của một đối tượng thuộc class đó có trong ảnh. Ta tạm gọi là box_max.
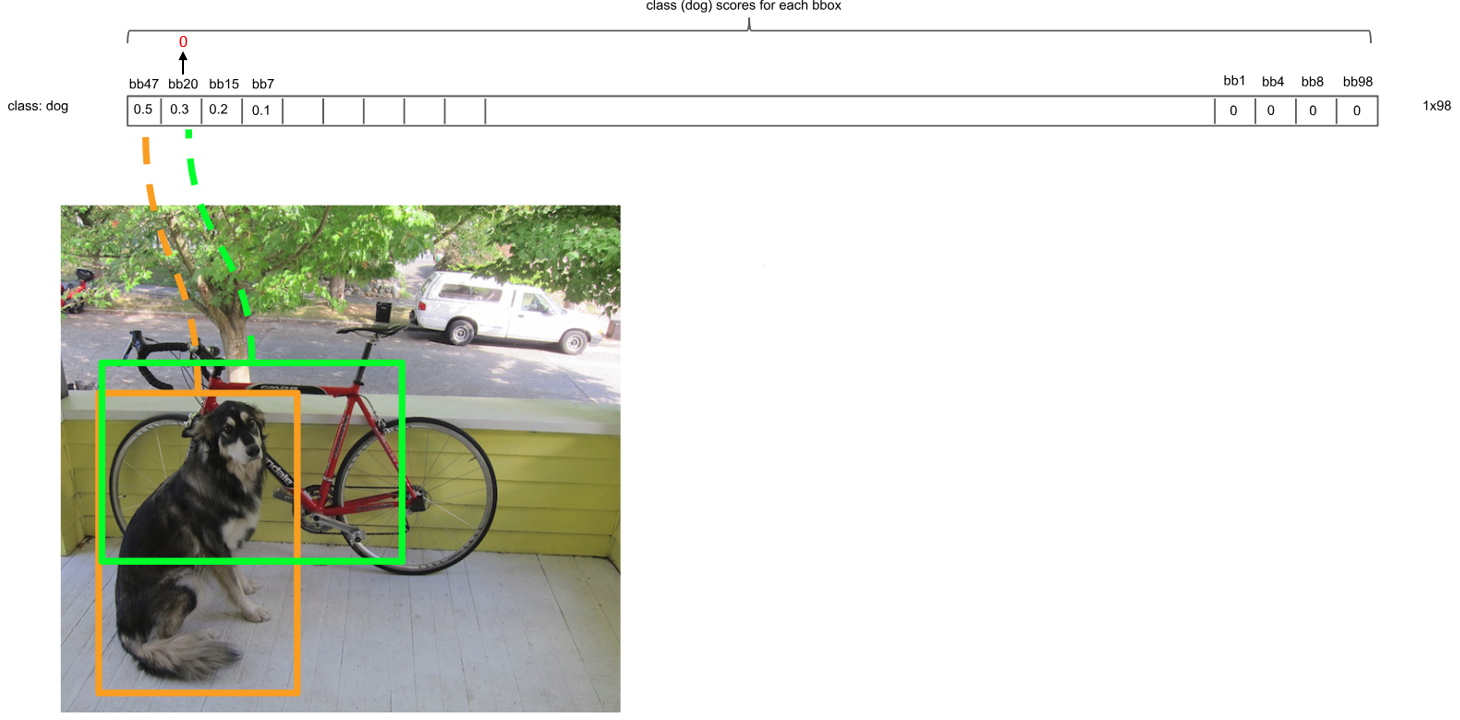
Bước 2: Xét bounding box có score cao thứ nhì (score khác 0). Nếu chỉ số IOU của box đang xét và box_max lớn hơn 0.5, ta sẽ xem như 2 bounding box này đang bao phủ cho cùng một đối tượng nên chỉ giữ lại box có score cao hơn (box_max). Sau đó, score của box đang xét được gán về 0. Ngược lại, nếu chỉ số IOU của hai box này nhỏ hơn 0.5, ta sẽ giữ lại cả 2 bounding box. Trong hình 7, box_max hiện tại là box thứ 47, box thứ 20 có chỉ số IOU với box thứ 47 lớn hơn 0.5. Do đó, score của box thứ 47 là 0.3 sẽ được gán bằng 0.
Bước 3: Lặp lại bước 2 với các bounding box có score thấp hơn (khác 0). Mục đích là để loại hết tất cả các bounding box đang bao phủ cùng một đối tượng với box_max.
Bước 4: Sau khi loại hết cái box cùng bao phủ một đối tượng với box_max, ta tiến hành xét duyệt xét box có score khác 0 và không cùng bao phủ một đối tượng với các box_max trước đó, gán nó là box_max. Sau đó tiếp tục lặp lại bước 1 cho đến khi đảm bảo rằng các box còn lại chỉ bao phủ một đối tượng riêng biệt thuộc class đang xét.
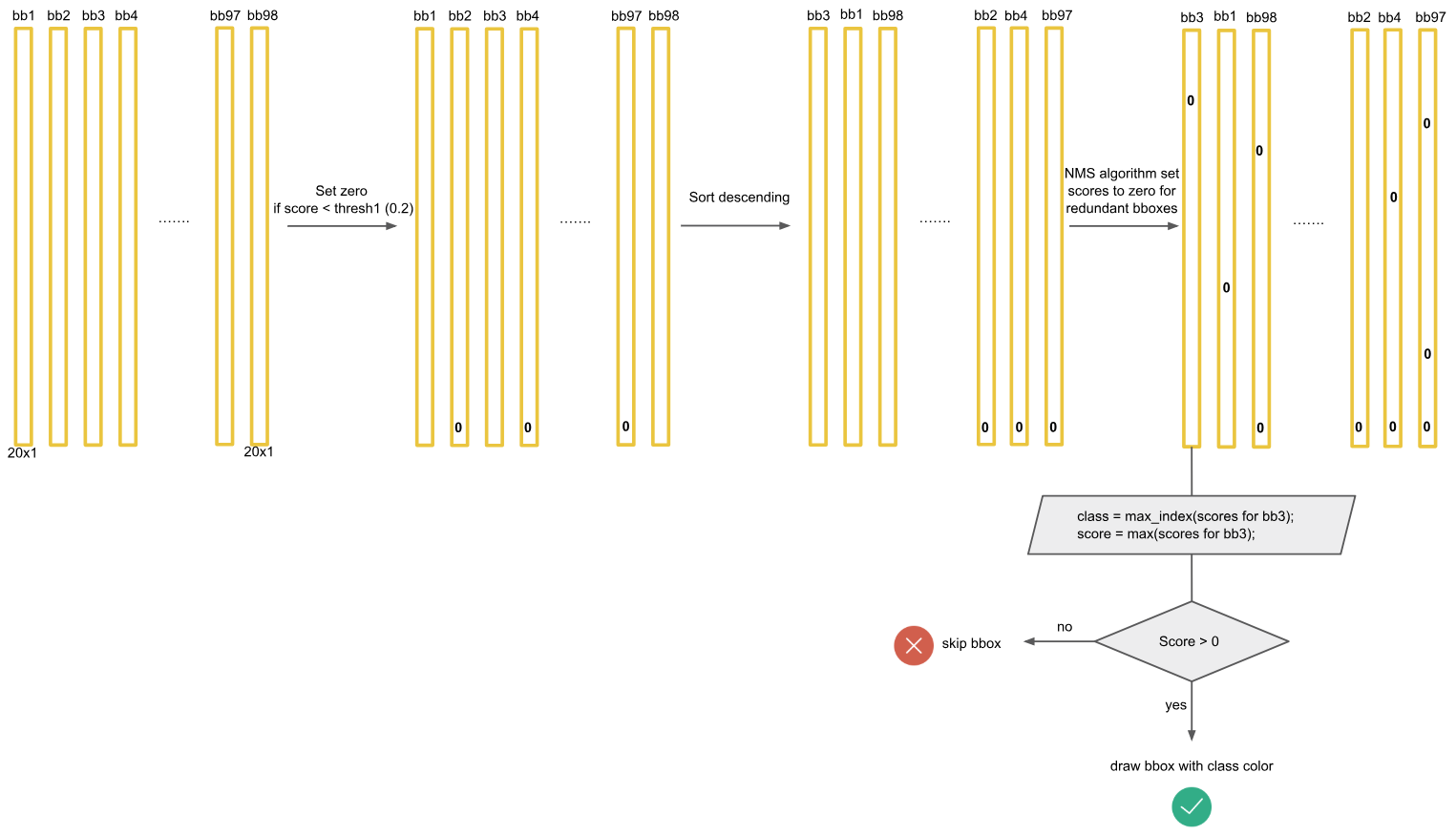
| Sau khi áp dụng thuật toán NMS lên tất cả các class của bài toán, ta sẽ tiến hành xét duyệt các bounding box có score khác 0 lần cuối cùng. Trong YOLO, một bounding box chỉ có thể là miền bao cho chỉ một đối tượng nên chúng chỉ có thể là biểu diễn cho class có xác suất điều kiện P(class_i | Object) cao nhất. Hình 8 mô tả quá trình xét duyệt các bounding box lần cuối cùng trước khi xuất ra kết quả ở hình 9. |